
Machine Learning Stochastic Descent And Minibatch Descent
Table of Contents
- Introduction
- Stochastic Gradient Descent
- Minibatch Gradient Descent
- Conventional Gradient Descent
- Comparison
Introduction
This exercise was an investigation into different methods for running gradient optimization iterations. The investigation is around single selection stochastic descent vs. mini-batch descent vs. conventional gradient descent.
For the exercise, I generated an arbitrary set of X and Y variables following the below:
-
p random variables of length n were drawn from an N(0,1) normal distribution to act as the column vectors for our feature matrix X. A column of 1s of length n was added to this to derive X.
-
Random errors
were drawn from an N(0, ) normal distribution of length n. is assumed be -
Y is taken to be equal to
where is p randomly drawn coefficients from a uniform distribution on [-1,1].
Our goal then is to estimate
Cost function is standardized at
Stochastic Gradient Descent
Instead of calculating the gradient on the entire training set, stochastic gradient descent involves drawing random individual samples from the training set and conducting gradient descent with that single sample, with replacement. This is then iterated as many times as necessary to derive an optimal approximation on the
The iteration function is
Over 10,000 iterations, we derived a final cost of 163,369 from stochastic descent. Below is a graphical example of what stochastic descent looks like on a topological function:
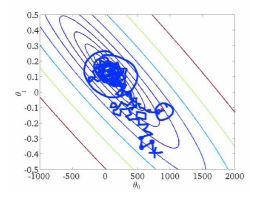
"Image credit: Serguei Maliar, Columbia University"
As shown, stochastic gradient descent takes random steps based on the probability weights of the sample distribution within the training set. Over many iterations, it converges roughly to optimal point, but with a fixed learning rate, may oscillate around the optimal point.
With a converging learning rate of, for example,
"Image credit: Serguei Maliar, Columbia University"
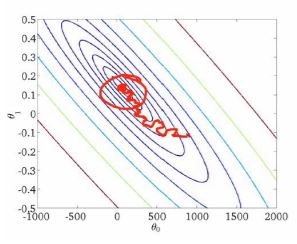
Minibatch Gradient Descent
Minibatch gradient descent differs from stochastic gradient descent in that instead of individual row samples, we instead select a random batch of samples of size
The iteration function is
Final cost for minibatch gradient descent is 149,905, much lower than stochastic gradient descent.
Conventional Gradient Descent
The conventional gradient descent selected is similar to what was discussed in the Gradient Descent post.
Final cost for minibatch gradient descent is 148,312, much lower than stochastic gradient descent, and lower than minibatch, but not significantly.
Comparison
For various values of p (number of features), n (number of samples in training set) and l (size of batch) that were tested, we can see a general trend in the comparison between the three gradient descent methods.
-
Generally stochastic descent is the fastest to run, given that it calculates on individual samples instead of multiple samples or the whole training set. Minibatch gradient descent is the 2nd fastest, with conventional gradient descent being the slowest.
-
Stochastic gradient descent does not necessarily give the model with the lowest cost. This is expected as it has a high degree of randomness with its sample selection process. Without a converging learning rate
, stochastic gradient descent may not even converge fully. Minibatch and conventional gradient descent tend to be fairly comparable, and hence the preferred gradient descent method would be minibatch due to its faster computation times. At certain levels of n and p, minibatch has a computation speed that is around 50% slower than stochastic, but almost 10 times faster than conventional gradient descent.